How to tell the difference between a model and a digital twin
标题(Title)
How to tell the difference between a model and a digital twin
从对数字孪生和模型的概念区分展开对数字孪生的讨论
摘要(Abstract)
本文主要讨论了“数字孪生”(Digital Twin)与“模型”(Model)的区别及其应用。
背景(Background)
数字孪生是一个热门概念,市场上多样且模糊的定义和解释的危险在于,可能导致人们将其视为炒作,一旦炒作和随之而来的反弹结束,最终的兴趣和使用水平(即“生产力高原”)可能远低于该技术的最大潜力。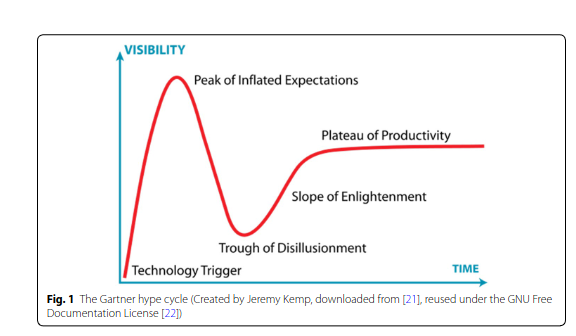
定义清楚数字孪生的含义具有重要意义。
主要内容(Main Content)
成功的实现数字孪生需要可信数据、可信模型、可信更新算法。
- 数字孪生的定义和背景
- 数字孪生的广泛应用:数字孪生技术被广泛应用于高价值制造、个性化医疗、石油精炼管理和城市规划的风险识别与缓解等领域。
- 定义的多样性和挑战:数字孪生的定义在各个领域和行业之间存在显著差异,甚至在同一领域内也可能存在多种定义。定义不明确可能导致人们对其的误解和低估,从而阻碍其潜力的发挥。
- 数字孪生与模型的核心区别
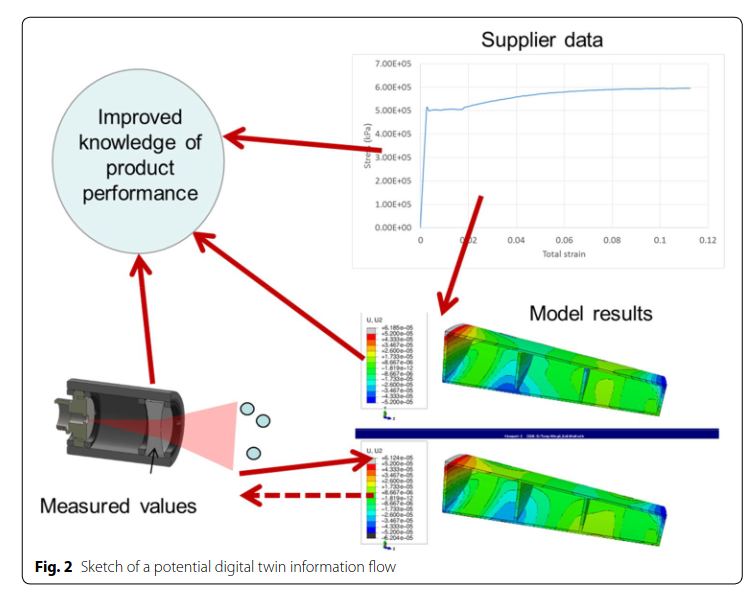
- 数字孪生的组成部分:数字孪生由三个重要部分组成:物体的模型、与物体相关的不断变化的数据集,以及根据数据动态更新或调整模型的方法。
- 模型与物理对象的关联:数字孪生必须与实际存在的物理对象相关联,没有物理对象的数字孪生只是一个模型。只有在原型阶段,数字孪生才在设计中具有意义。
- 数字孪生的应用和优势
- 制造业中的应用:数字孪生技术在制造业中可以用于增强在线测量过程、智能组装、装配验证、性能保证、维护调度和智能维护、以及寿命预测等方面。
- 医学中的应用:在医学领域,数字孪生可以用于个性化药物特性、植入物和假肢几何形状、以及治疗计划的定制,从而提高治疗效率和效果。
- 科学研究中的应用:在基础科学研究中,数字孪生可以用于实验设备的特性评估和不确定性分析,从而确保实验结果的可靠性。
- 选择适合的模型
- 物理驱动模型与数据驱动模型:数字孪生可以使用任何足够准确地代表物理对象的模型。理想情况下,数字孪生应使用基于物理的模型,但计算成本和准确性是重要的考虑因素。数据驱动模型仅在数据充足且输入参数空间已知时才可靠。
- 混合模型的方法:在某些情况下,可以结合高精度的物理模型和快速运行的替代模型(如代理模型)来实现更快的参数估计和不确定性分析。
评价和感想(Evaluation and Reflections)
模型在数据的驱动下,成为了数字孪生体。通过模型 + 传感器实时数据,我们可以对物理实体目前的状态充分理解,而通过历史数据,用机器学习的方法,可以实现优化和故障预测之类的工作。
未来研究方向(Future Research Directions)
- 信任模型和数据
- 模型验证和验证:
- 需要对模型进行严格的验证和确认。这包括处理具有多个耦合模型的复杂系统,如发动机的热流、流体流动和应力模型。
- 处理耦合模型通常需要序列化解决方案,引入插值和处理误差,需要在验证中考虑这些误差。
- 统计不确定性:
- 由于存在不确定性,验证需要作为一个统计过程进行。所有测量都需要附带不确定性,模型输入和输出也是如此。
- 比较数据和模型结果时,需要估计值的一致性概率,而不是简单的“5%的误差即可接受”的方法。
- 数据的信任
- 元数据记录:
- 传感器数据需要附带元数据(如传感器类型、精度、环境敏感性、校准日期等),以确保数据的可靠性和未来可用性。
- 元数据的标准化对于跨行业的数据使用和数据搜索至关重要。
- 历史和策划数据:
- 有效使用历史数据需要良好的数据管理和搜索能力,确保数据的可查找性、可访问性、互操作性和可重用性(FAIR原则)。
- 数据与模型的关系
- 数据集构建:
- 数据集不仅需要用于几何、材料属性、边界条件和负载的定义,还需要用于更新那些制造或使用过程中可能变化的模型参数。
- 例如,发电站模型可能包括随时间变化的涡轮机效率曲线,通过实时功率和角速度数据更新这些曲线以支持智能维护。
- 数据缩减技术:
- 大量传感器数据需要通过数据缩减技术进行处理,以识别对参数更新最有影响的测量。例如,奇异值分解(SVD)等线性技术,以及处理非线性和瞬态模型的新方法。
- 更新过程
- 优化和数据同化:
- 对于少量参数,简单的优化方法即可。对于大量参数,数据同化方法(如在气象学中使用的初始条件更新)可能更合适。
- 高计算成本的模型可能需要使用代理模型,以便在复杂系统的实时更新和不确定性评估中提高计算效率。
- 代理模型开发:
- 代理模型(如高斯过程建模)需要一组已知输入值的结果作为训练集,以构建高效的近似模型。这些模型不仅提供预测值,还提供误差估计,有助于识别最有助于降低误差的数据区域。
- 模型降阶技术
- 模型降阶:
- 使用模型降阶技术(如部分微分方程的降阶方法)来减少计算成本。这些方法通过特征或模式来描述系统,例如傅里叶级数分解时间信号。
数字孪生体理解——以风力涡轮机为例
数字孪生体的组成
- 模型:
- 物理模型:基于物理定律和公式构建的模型,可以模拟风力涡轮机的结构、空气动力学特性、热力学特性等。
- 数据驱动模型:利用历史数据构建的统计或机器学习模型,可以用于预测和优化。
- 传感器实时数据:
- 实时监测物理实体(如风力涡轮机)的关键参数,如叶片振动、轴承温度、风速和风向等。
- 这些数据被输入到模型中,使模型能够反映物理实体的当前状态。
数字孪生体的功能
- 理解当前状态:
- 通过传感器实时数据,数字孪生体能够提供物理实体的实时状态监控。
- 动态更新模型,使其始终反映当前的运行状况,帮助运营人员做出准确的判断和及时的响应。
- 优化:
- 使用历史数据和机器学习方法,数字孪生体可以识别最佳运行参数和操作策略。
- 例如,通过分析历史风速和能量输出数据,可以优化风力涡轮机的叶片角度和转速,从而提高效率。
- 故障预测:
- 数字孪生体利用历史数据和机器学习算法来识别潜在故障的早期迹象。
- 例如,通过分析轴承温度和振动数据,可以预测轴承的磨损和故障,从而提前安排维护,避免灾难性故障。
具体步骤
- 数据采集:
- 通过传感器实时采集物理实体的运行数据。
- 结合历史数据,形成完整的数据集。
- 模型更新:
- 使用实时数据更新物理模型,确保模型反映当前状态。
- 利用历史数据和机器学习算法,不断改进模型的预测能力。
- 分析和决策:
- 基于实时数据和更新的模型进行状态监控和异常检测。
- 使用机器学习算法进行故障预测和优化决策。
- 实施优化和维护:
- 根据模型的优化建议调整运行参数,提高运行效率。
- 根据预测的故障信息,提前安排维护,避免非计划停机。
参考文献(References)
Wright, L., & Davidson, S. (2020). How to tell the difference between a model and a digital twin. Advanced Modeling and Simulation in Engineering Sciences, 7, 1-13.
https://scholar.google.com/scholar?output=instlink&q=info:EetkrnXmxJ0J:scholar.google.com/&hl=zh-CN&as_sdt=0,5&scillfp=9269107100885242647&oi=lle
-------------本文结束感谢您的阅读-------------