LLM4PLC Harnessing Large Language Models for Verifiable Programming of PLCs in Industrial Control Systems
标题(Title)
LLM4PLC Harnessing Large Language Models for Verifiable Programming of PLCs in Industrial Control Systems
利用大模型为PLC自动生成代码,PLC用于工业控制。
arXiv:2401.05443v1 [cs.SE] 8 Jan 2024
摘要(Abstract)
大语言模型在自动化生成代码方面已经起到重要作用,但是其应用在自动控制领域仍然面临挑战。类似用于PLC的代码面对如下挑战。
- 训练样本少
- 对代码的可靠性要求极高,这些代码会直接作用于物理世界,稍有偏差就可能造成重大损失。(仿真是解决问题的一个思路,如果PLC自动生成代码,然后先在仿真环境跑通,再部署到产线上,这应该是这个方向的进一步创新。而且仿真的结果可以直接反馈给LLM,方便其进一步迭代,这将比本文描述的方案更为高效。)
本文提出了LLM4PLC,用于自动化生成PLC代码,为了解决上述的问题,引入了grammar checkers, compilers and SMV verifiers确保生成代码的可靠性。对大模型进行微调和针对性的提示词工程。
最后本文生成的代码在MFTB平台上进行了测试,证明了该方法对PLC代码有较大提升。
背景(Background)
PLC是特定领域的实时计算机,运行专门的程序,并采用IEC 61131-3标准下的五种编程范式之一。其中,结构化文本(ST)由于其语法和结构与传统编程语言相似,适合使用最先进的技术进行自动代码生成。
然而,开发可靠且安全的PLC软件非常复杂且耗时。为了提高工程效率,本文提出了LLM4PLC框架,该框架通过使用大型语言模型(LLM)自动生成PLC代码,并结合用户反馈和外部验证工具,确保代码的安全性和有效性。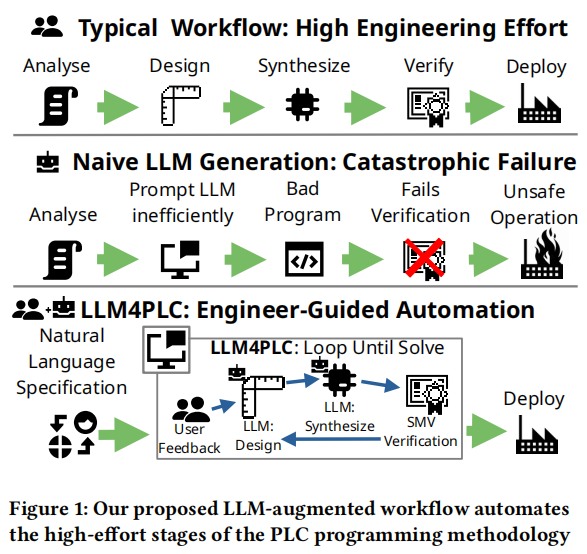
主要内容(Main Content)
本文采用的方法基于现有的PLC软件工程、形式验证方法以及最先进的LLM提示和参数高效微调(PEFT)技术,包括低秩适应(LoRAs)。本节提供了每个领域的必要背景知识,并介绍了我们在所提出方法中采用的设计选择动机。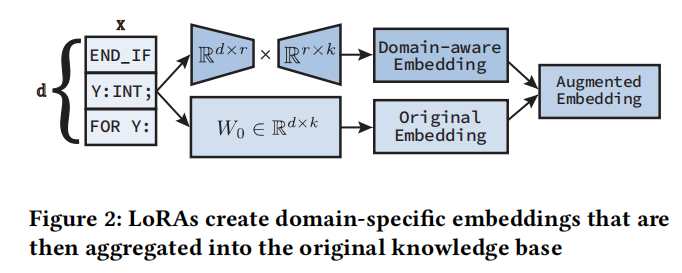
大型语言模型(LLM)
大型语言模型(LLM)利用Transformer架构中的注意力机制来建模不断增加长度的序列。Transformer模型的核心是自注意力机制,它计算序列中每对标记的注意力分数,从而允许在序列内长距离之间的依赖关系和关系。所有主要的LLM都使用下一个标记预测(NTP)方案一次生成一个标记。
模型驱动设计(MBD)
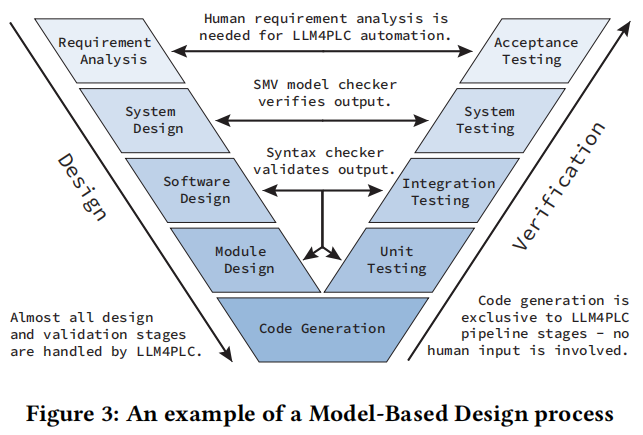
模型驱动设计(MBD)是一个工程范式,它利用数学和图形建模来促进复杂系统的分析、实现和模拟。通过使用有限状态机(FSM)显式规划来优化PLC扫描周期,每个FSM状态负责单一操作,使执行过程可预测且易于调试。在自然语言规范的MBD提示中,我们约束LLM遵循FSM设计以解决方案。
语法检查器和形式验证
- 语法检查器:在将候选代码转换为可运行程序的第一步是检查其是否符合编程语言的标准。如果发现任何错误,这些错误会反馈到我们的管道中以创建下一个阶段的‘纠正提示’。通过集成语法检查器在LLM代码生成管道中,可以更深入地了解代码缺陷,并更好地准备LLM采取纠正措施。
- 形式验证:通过符号模型检查进行程序和算法的形式验证是部署PLC代码到危险环境中的关键步骤。形式验证工具采用候选代码以及操作的严格约束来证明功能正确性。我们的方法利用接受的静态分析知识在验证管道中使用这些工具来验证LLM生成的代码。
实验设置
为了进行这项研究,我们针对GPT-3、GPT-4、Code Llama 7B和Code Llama 34B进行了全面评估。这些模型代表了当前最先进的一般用途语言模型(GPT-3和GPT-4)和专为代码生成设计的模型(Code Llama 7B和Code Llama 34B),使我们能够研究性能与计算资源之间的权衡。
提示工程
我们采用了两种提示类型,即零样本提示和单样本提示来生成LLM的输出。单样本提示包含结构化文本语法和代码元素的代表性示例,从而为改进代码生成提供上下文线索。而零样本提示仅请求代码生成,没有任何上下文指导。
LLM微调
我们通过创建低秩适应(LoRA)对Code Llama 7B和Code Llama 34B进行了微调。GPT-3.5和GPT-4不提供LoRA训练接口,因此我们使用这些模型的默认配置。然后,我们利用这些知识训练了一组用于代码补全和代码修复任务的LoRA,每个模型两组。
数据集
我们从OSCAT IEC 61131-3库生成了训练、验证和测试数据集。具体而言,我们运行自动化测试剔除OSCAT数据集中不合格的ST文件,然后创建三个独立的数据集来广泛测试我们的管道能力:
- 生成数据集:即剔除所有不可编译文件后的OSCAT数据集。
- 补全数据集:通过随机截断生成数据集中的文件来创建,模拟LLM的代码补全能力。
- 修复数据集:通过从生成数据集中随机删除行,直到生成的ST文件无法编译为止,用于测试LLM解决特定语法错误的能力。
测量指标
我们的测量指标包括通过率、编译器错误数量和代码质量的人类评估。通过率使用pass@k指标评估,编译器错误率提供对我们方法稳健性的洞察,代码质量评估则通过专家小组的评分来完成。
测试平台
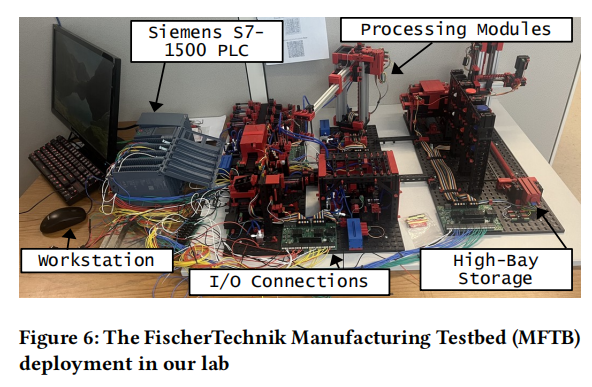
我们在实验室部署了FischerTechnik制造测试平台(MFTB),这是一个集成平台,用于模拟常见制造过程的小型版本。MFTB是一个复杂的网络物理系统,集成了各种输入和不同类型的输出,用于研究和验证自动化、数字控制系统和操作效率。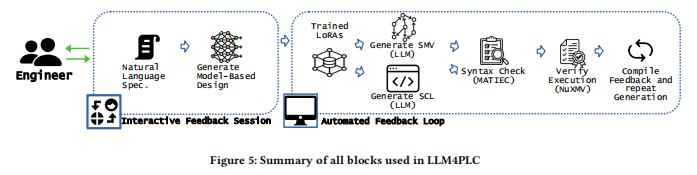
实验结果
在本节中,我们展示了我们的方法——LLM4PLC的实证评估结果。我们通过三个关键指标来衡量方法的有效性:通过率、编译器错误计数和人工评估的代码质量。我们还比较了每种解决方案所需的工程时间。这些指标为我们的方法提供了全面的评估,涵盖了代码生成过程中的准确性、鲁棒性和实用性 。
通过率
为了评估通过率,我们通过LLM4PLC管道的各个阶段对40个专用测试文件集进行了测试。对于每个生成的40个输入文件,我们确定了通过率。结果表明,随着我们在各个阶段添加更多组件,通过率逐步提高,反映了我们提出的方法的有效性。特别是在包含单次提示、LoRA和语法检查器的最终阶段,Code Llama 34B模型的通过率达到了72.5% 。
编译器错误计数
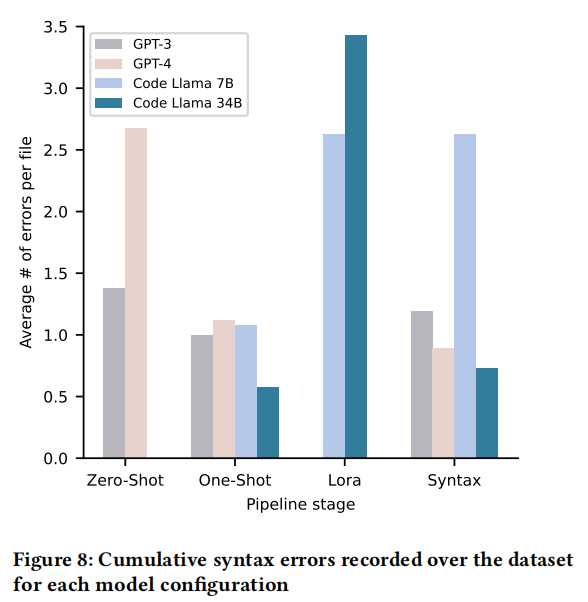
接下来,我们计算了每个输出代码文件生成的编译器错误数量。然后我们对测试文件集中的错误数量进行平均,以规范化结果。结果显示,LoRA和语法检查配置的错误数高于单次提示。然而,随着管道的进展,我们的管道能够纠正这些错误,使得LoRA和语法检查的编译通过率高于单次提示配置 。
人工质量评估
代码质量的人工评估使用了由各种PLC编程经验的专家组成的小组。专家们根据预定的标准评估生成的代码,包括正确性、可维护性和符合行业编码标准。高分表明我们的方法在生成可读且易于维护的代码方面的实用性,显示出其无缝集成到现有人工驱动开发过程中的潜力 。
工程时间
在选择GPT基础的解决方案、LoRA增强的LLM和传统的手工编程技术时,工程时间是一个关键问题。我们的实证研究显示了每种方法所需时间的显著差异。GPT模型的设置非常高效,通常只需几分钟即可集成API并开始代码生成。而为现有开源模型(如Code Llama)设置LoRA则需要大量时间来收集数据和进行训练。手工编程PLC尽管是一个理解度很高的方法,但也是最耗时的,通常比基于LLM的方法需要更多的时间和专业人力资源投入 。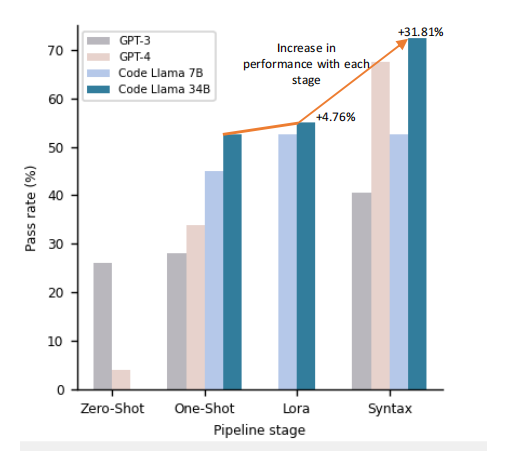
评价和感想(Evaluation and Reflections)
LLM4PLC方向非常扎实的工作,可以复现作为后续研究的基础。
未来研究方向(Future Research Directions)
结合仿真进行进一步优化,降低成本的同时优化代码生成、自反馈机制。
参考文献(References)
https://arxiv.org/pdf/2401.05443
Fakih, M., Dharmaji, R., Moghaddas, Y., Araya, G. Q., Ogundare, O., & Faruque, M. A. A. (2024). LLM4PLC: Harnessing Large Language Models for Verifiable Programming of PLCs in Industrial Control Systems. arXiv preprint arXiv:2401.05443.